
毕业设计:基于机器学习的食物热量卡路里估算方法 人工智能 算法 Faster R-CNN
毕业设计:基于机器学习的食物热量卡路里估算方法过综合运用深度学习和计算机视觉技术,提出了一种创新的食物热量卡路里估算方法。该方法基于智能移动设备,通过拍摄食物照片进行计算,实现了快速、准确的卡路里估算。本研究为计算机毕业设计提供了一个创新的方向,结合了深度学习和计算机视觉技术,为毕业生提供了一个有意义的研究课题。对于计算机专业、软件工程专业、人工智能专业、大数据专业的毕业生而言,提供了一个具有挑战
目录
前言
📅大四是整个大学期间最忙碌的时光,一边要忙着备考或实习为毕业后面临的就业升学做准备,一边要为毕业设计耗费大量精力。近几年各个学校要求的毕设项目越来越难,有不少课题是研究生级别难度的,对本科同学来说是充满挑战。为帮助大家顺利通过和节省时间与精力投入到更重要的就业和考试中去,学长分享优质的选题经验和毕设项目与技术思路。
🚀对毕设有任何疑问都可以问学长哦!
选题指导:
大家好,这里是海浪学长毕设专题,本次分享的课题是
🎯基于机器学习的食物热量卡路里估算方法
设计思路
一、课题背景与意义
随着人们对健康饮食的关注度提高,食物卡路里的准确估算变得越来越重要。然而,传统的卡路里估算方法通常需要复杂的食物称量或基于一般性数据的估算,存在效率低下和误差较大的问题。基于机器学习的食物热量卡路里估算方法的研究具有重要的现实意义。通过结合深度学习和计算机视觉技术,可以利用智能移动设备从食物照片中准确估算卡路里,为用户提供方便、快速、准确的卡路里摄入控制方法,有助于促进健康饮食和营养管理。
二、算法理论原理
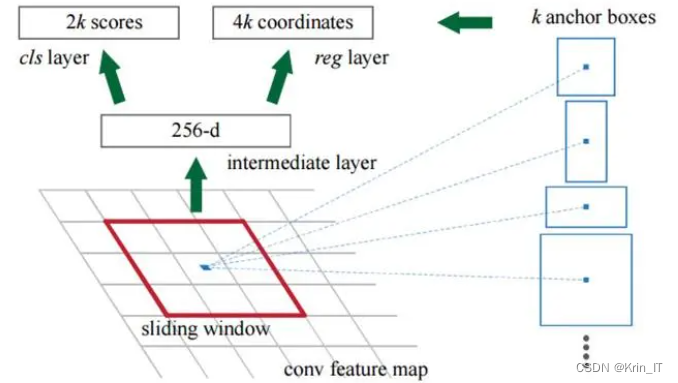
2.1 Faster R-CNN
卡路里估算系统的框架,包括照片获取、检测、分割、体积估算和卡路里估算等步骤。首先,利用目标检测算法对获取的照片进行食物和参照物的检测,然后利用图像分割算法获取准确的食物轮廓。接下来,根据参照物和食物轮廓计算食物的体积。最后,通过查找食物相关信息来估算食物的卡路里。本研究采用Faster R-CNN目标检测算法来标记食物和参照物的位置和类别。经过Faster R-CNN处理后,食物和参照物的位置已经确定,但为了得到更精确的食物边缘以提高体积估算的准确性,采用GrabCut图像分割方法获取食物的精确轮廓。这个系统框架为卡路里估算提供了一种有效的方法,不需要用户参与就能实现图像分割,从而提高了准确性和效率。

Faster R-CNN的训练过程可以总结如下:
-
初始化:使用ImageNet模型初始化一个独立的Region Proposal Network(RPN)网络。
-
训练RPN网络:使用ImageNet模型初始化Faster R-CNN,并将RPN网络的输出作为Faster R-CNN的输入,训练一个完整的Faster R-CNN网络。在这个阶段,两个网络的每一层的参数是完全独立的,没有共享。
-
参数替换:对于Faster R-CNN和RPN共享的网络层,使用第二步训练得到的Faster R-CNN网络的参数进行替换;对于两个网络不共享的网络层,采用默认的方法进行初始化。然后再次训练RPN网络,但只更新RPN特有的那些网络层。
-
固定共享网络层:固定Faster R-CNN与RPN共享的网络层,利用第三步训练得到的RPN的输出,继续训练Faster R-CNN。在训练过程中,只更新Faster R-CNN特有的网络层参数。

2.2 体积估算方法
算法基于形状的食物体积估算,通过获取食物和标定物的精确轮廓,利用标定物计算比例系数,然后根据食物的形状选择相应的体积计算公式,并结合俯视图、侧视图以及计算得到的比例系数进行食物体积的估算。这种方法可以减少误差并提高卡路里估算的准确性。通过输入食物俯视图、食物侧视图、标定物俯视图和标定物侧视图,算法依次计算侧视图比例系数PB、俯视图比例系数PA,然后根据食物的形状选择适当的体积计算公式,并结合比例系数和图像信息进行食物体积的计算,最后输出食物的体积。

将食物形状分为四种类型:椭球体、柱体、圆环体和其他形状。通过获取食物的俯视图A和侧视图B,可以构建食物的三维模型进行体积估算。在俯视图A中,假设食物占据m行,其中第i行(i=1, 2, ..., m)食物占据LiA个像素。记LiAmax为LiA中的最大值,表示食物所占的最大像素个数SA为所有LiA的总和。这样,通过分析食物在俯视图和侧视图中的像素分布情况,可以推断出食物的形状并构建相应的三维模型,然后利用体积计算公式进行食物体积的估算。

根据食物的形状和对应的公式,结合俯视图和侧视图的像素信息以及计算得到的比例系数,可以进行食物体积的估算。通过对不同形状的食物应用相应的公式,结合俯视图和侧视图的像素信息以及比例系数,可以进行准确的食物体积估算。这种方法可以减少误差,提高卡路里估算的准确性。:
- 对于椭球体形状的食物,利用侧视图B中食物所占像素的长度进行计算。通过计算每一行像素长度的平方和,并乘以侧视图比例系数PB的立方,再乘以π/4,可以估算出椭球体食物的体积。
- 对于柱体形状的食物,利用俯视图A中食物所占像素的总数SA和俯视图比例系数PA,乘以侧视图中食物所占行数n乘以侧视图比例系数PB,可以得到柱体食物的体积估算结果。
- 对于圆环体形状的食物,需要考虑食物俯视图中的中空部分。记中空部分所占用的像素数量为SAE。通过计算(SA - SAE)乘以俯视图比例系数PA,再乘以侧视图中食物所占行数n乘以侧视图比例系数PB,可以进行圆环体食物的体积估算。

相关代码示例:
import math
# 定义体积估算函数
def estimate_volume(shape, top_view_pixels, side_view_pixels, scale_factor):
if shape == 'sphere':
radius = math.sqrt(top_view_pixels / math.pi)
volume = (4/3) * math.pi * math.pow(radius, 3)
elif shape == 'cylinder':
radius = math.sqrt(top_view_pixels / math.pi)
height = side_view_pixels * scale_factor
volume = math.pi * math.pow(radius, 2) * height
elif shape == 'cube':
side_length = math.sqrt(top_view_pixels)
volume = math.pow(side_length, 3)
else:
raise ValueError("Invalid shape specified.")
return volume
shape = 'sphere'
top_view_pixels = 1000
side_view_pixels = 500
scale_factor = 0.5
estimated_volume = estimate_volume(shape, top_view_pixels, side_view_pixels, scale_factor)
# 打印结果
print("Estimated volume: ", estimated_volume)三、检测的实现
3.1 数据集
为了构建有效的食物热量卡路里估算模型,本研究作者自制了一个全新的数据集。作者在实际生活中收集了大量食物照片,并利用计算机视觉技术进行预处理和标注。通过精细的数据收集和标注工作,作者成功构建了一个多样化的食物热量数据集,包括各种不同类型的食物和多个热量范围。这个自制的数据集为研究提供了更准确、可靠的数据基础,使得食物热量卡路里估算模型能够更好地适应真实世界的情况,并为食物热量管理的准确性提供有力的支持。相信这个自制的数据集将对食物热量卡路里估算方法的研究和应用产生积极的影响。

数据扩充是一种有效的技术,通过对现有数据集进行变换和增强操作来生成更多样本。这种方法可以解决数据不足的问题,提高深度学习模型的性能和泛化能力。数据扩充通过模拟真实世界的变化和噪声,使模型能够训练和适应更多不同情况和环境。合理选择和设计数据扩充操作可以避免引入不必要的偏差或噪声,确保生成的样本能够代表真实数据的分布。通过数据扩充,模型可以更好地适应多样性和复杂性的数据,提高在实际应用中的效果。
3.2 实验环境搭建
实验平台为Windows 7 (64位),显卡型号为英伟达GTX 1070。Faster R-CNN代码基于Matlab,GrabCut图像分割以及体积。Matlab版本号为R2014b,Visual Studio版本号为2013,OpenCV版本号为3.0,CUDA版本号为8.0。
3.3 实验及结果分析
在使用训练集对Faster R-CNN进行训练后,对测试集中正确检测的图片进行了体积估算实验。实验中仅使用Faster R-CNN在测试集中正确检测的图片,每张图片包含一张俯视图和一张侧视图。通过剔除Faster R-CNN误识别或未识别的样本后,得到了体积估算实验所用的各类样本数。

对不同的食物采用不同的体积估算方法可以使估算结果更接近真实值。不同食物的形状和结构差异较大,因此采用统一的体积估算方法可能无法准确估算每种食物的实际体积。通过针对不同的食物类型开发特定的体积估算方法,可以利用食物的特性来提高估算的准确性。例如,对于某些食物,可以基于其形状的特征参数进行体积估算,而对于其他食物,可以使用特定的体积计算公式或补偿系数来修正估算误差。

相关代码示例:
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
# 加载预训练的深度学习模型(例如,ResNet)
model = models.resnet50(pretrained=True)
model.eval()
# 图像预处理
preprocess = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]),
])
# 加载类别标签
with open('labels.txt') as f:
labels = [line.strip() for line in f.readlines()]
# 加载图像
image_path = 'food_image.jpg'
image = Image.open(image_path)
# 图像预处理和模型推断
input_tensor = preprocess(image)
input_batch = input_tensor.unsqueeze(0)
with torch.no_grad():
output = model(input_batch)
# 获取预测结果的索引
_, predicted_idx = torch.max(output, 1)
# 估算卡路里
calories_per_class = [50, 100, 150, 200] # 每个类别的卡路里估算值
predicted_calories = calories_per_class[predicted_idx.item()]
# 打印结果
predicted_label = labels[predicted_idx.item()]
print("Predicted food: ", predicted_label)
print("Estimated calories: ", predicted_calories)创作不易,欢迎点赞、关注、收藏。
毕设帮助,疑难解答,欢迎打扰!
最后
更多推荐

 19
19 0
0- 0



 已为社区贡献8条内容
已为社区贡献8条内容

所有评论(0)