目录
1.什么是模式识别
1.1人工智能和模式识别
1.2信息感知
1.3计算机模式识别
1.4模式识别应用
1.5模式识别发展简史
1.6相关问题和领域
2.模式识别形式化
2.1模式和模式识别
2.2模式表示
2.3特征空间
2.4特征空间中的分类
2.5一个例子
3.模式识别系统流程
4.模式分类器设计
4.1分类器训练过程
4.2训练-评价流程
4.3数据划分方式
4.4泛化性能
5.模式识别方法分类
5.1根据表示方式分类
5.2统计/结构方法对比
5.3学习方法分类
5.4生成/判别模型
1.什么是模式识别
1.1人工智能和模式识别
•
人工智能(Artificial Intelligence, AI)
:
构造智能机器 (智能计算机、智能系统
)
的科学和工程,使机器模拟、延伸、扩展人类智能
•
人类智能
–
感知:看
(
视觉
)
、听
(
听觉
)
、摸
(
触觉
)
、闻
(
嗅觉
)
、尝
(
味
觉
)
–
学习:有教师学习,自学习
–
思维:推理、回答问题、定理证明、下棋等
–
行为:表情、拿物、走路、运动
人工智能研究内容
• 机器感知(模式识别)
– 模式分类、模式匹配
– 计算机视觉、图像视频分析
– 语音识别、自然语言理解
• 机器学习
– 从数据或经验学习模型或程序
– 监督学习、无监督学习、半监督学习等
• 机器思维(问题求解)
– 专家系统、自动问答、机器定理证明、下棋等
• 智能行为
– 机器人动作、自动驾驶、无人机等
模式识别在
AI
中的地位
•
模式识别:
机器感知环境,从环境获取信息和知识
– 视觉感知:
从图像识别文字、物体、行为等,从而理解周围环境
– 听觉感知:
从声音和文本识别场景、理解语言和获取知识
1.2信息感知
感知:从环境获取信息
人和动物通过感知从周围环境获取信息。感知就是模式识别过程。
1.3计算机模式识别
•
模式识别:使计算机模仿人的感知能力,从感知数据中提取信息(判别
物体和行为、现象
)的过程
1.4模式识别应用
安全监控
(身份识别、行为监控、交通监控)
空间探测与环境资源监测
(卫星
/
航空遥感图像)
智能人机交互
(表情、手势、声音、符号)
机器人环境感知
(视听触觉)
人类健康
(医学图像、体测数据)
工业应用
(零部件
/
物品分类、损伤检测)
文档数字化
(历史书籍报纸、档案、手稿、标牌等)
网络搜索、信息提取和过滤
(文本、图像、视频、音频、多媒体 )
舆情分析
(互联网、大数据)
有些生物特征(如虹膜、指静脉)精度高,但是需要客户配合。
有些(如签名、步态)精度相对较低,但是不需要配合,有适合其应用的场合。
智能交通、无人驾驶:
交通标志识别、道路识别、车辆识别、行人识别等
1.5模式识别发展简史
•
生物“模式识别”
(
心理学
)
•
光学
/
机械模式识别
–
第一个光学字符识别
(OCR)
专利:
1929
•
现代模式识别:电子计算机发明以后
–
先期统计学基础
(19
世纪以前
)
:
Bayes, Gauss, Fisher
等
–
早期统计模式识别:
IBM (1950s-)
–
第一个“模式识别”学术会议:
1966 (
波多黎各
)
–
早期模式识别教材:
Fukunaga (1972), Duda&Hart (1973)
–
第一次国际模式识别大会
(ICPR)
:
1972
–
国际模式识别协会
(IAPR)
:
1974
筹建,
1978
年正式成立
模式识别方法演化
•
核心内容:模式分类
–
特征提取
/
选择、聚类分析、分类器设计(机器学习)
•
统计模式识别:
1950s-
•
句法、结构模式识别:
1970s-
•
人工神经网络:
1980s-
•
支撑向量机、核方法:
1990s-
•
多分类器、集成学习:
1990s-
•
Bayes
学习:
1990s-
•
1990s-:
模式识别技术大规模应用
•
2000s-:
半监督学习、多标签学习、概率图模型
•
最近:迁移学习、稀疏表示、深度学习
(
神经网络复活
)
1.6相关问题和领域
模式识别相关问题
•
数据预处理
–
视频、图像、信号处理等
•
模式分割
–
检测定位、背景分离、模式
-
模式分离
•
运动分析
–
目标跟踪、运动模式描述
•
模式描述与分类
–
特征提取
/
选择、模式分类、聚类、机器学习
•
模式识别应用研究
–
针对具体应用的方法与系统
相关领域:模式识别-机器学习-数据挖掘
2.模式识别形式化
2.1模式和模式识别
•
模式的两个层次
–
样本
(Sample, instance, example)
–
类别
(Class, category)
例如:100个样本、10个类别

• 模式识别核心技术:
模式分类
比如下图:
检测出:
2-class (binary)
判别出:
2-class, multi-class
分类器设计:
机器学习
相关问题:特征提取、特征选择
2.2模式表示
模式表示有两个方面,一是识别对象表示,二是分类器表示
•
识别对象表示
:
特征
–
特征矢量:
x
= x
1
,
x
2
,…,
x
n
]
x
1
,
x
2
,…,
x
n
]![]^{T}](https://latex.csdn.net/eq?%5D%5E%7BT%7D)
–
特征空间
(
线性空间、欧式空间
)
–
问题:
特征提取
、
特征选择

2.3特征空间
• 特征矢量表示的好处
–
一个模式
(
样本
)
对应空间中的一点
–
容易计算样本之间的距离
/
相似度
–
大量数学工具,分类器模型核学习方法,性能分析
• 欧式空间特性
– 欧式距离:坐标系不变性
–
Metric
d(x
1
,x
2
)+d(x
1
,x
3
)>d(x
2
,x
3
)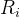
d(x
1
,x
2
)-d(x
1
,x
3
)<d(x
2
,x
3
)

2.4特征空间中的分类
•
分类:空间划分
–
距离度量
/
相似度:mind(x,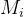 )
)
–
决策区域:=arg max f(x,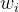 )
)

•
线性可分
/
不可分

•
线性
/
非线性判别
2.5一个例子
下面以鱼分拣的例子来说明

图中左边这个是三文鱼(Salmon),右边是黑鲈鱼(Sea bass)
下面来构建长度特征分类

接着构建亮度特征分类

可以发现亮度比长度分类结果好很多,但是可能还有更好的特征,这里不展开了,感兴趣的朋友可以自行查阅资料
以上两个都是一维特征(长度 鱼身亮度)的分类结果下面我们来看看二维特征的分类:
使用线性分类器

可以发现多个特征组合比单个特征具有更好的可分性
接着我们可以将决策边界改为平滑曲面试试:
使用
非线性分类器
最后再使用
最近邻分类器看看:
值得注意的是复杂分类器划分能力更强,但计算复杂,而且可能产生过拟合
3.模式识别系统流程
下面我们使用一个文档分析系统的例子来看看模式识别的一般流程:
这是一个文档分析系统的分析过程


对于这样一个文档,其分析流程如下:
1. 数据采集:首先通过扫描仪、相机或数字笔获取文档图像。
2. 布局分析:对采集到的图像进行布局分析,确定文本的位置和方向。
3. 字符分割:在布局分析的基础上,对图像中的文字进行字符分割,即把图片中的每个字符切分开来。
4. 识别:对分割出的字符进行预处理、特征提取和分类,以识别出这些字符。
5. 后处理:对识别出的字符进行校正和排序,以提高识别结果的准确性和可读性。
由此我们归纳出模式识别的完整流程如下:

模式识别的完整流程通常包括以下步骤,每一步都是为了提高识别的准确性和效率:
1.数据采集(Data Acquisition):
这是流程的第一步,涉及从原始源获取数据。数据可以是图像、声音、文本或其他任何形式。在文档分析的情况下,这通常涉及到使用扫描仪、摄像头或其他设备将文档转换为数字格式。
2.数据分割(Segmentation):
在这一步中,系统会将数据分割成更小的部分,以便于后续处理。在图像处理中,这可能包括将图像分割成多个区域或对象。例如,在文档分析中,这可能涉及到区分文本、图像、表格等不同元素。
3.数据预处理(Pre-processing):
数据预处理是为了改善数据质量,使其更适合进行特征提取和分类。这可能包括去噪、对比度增强、大小归一化、二值化等操作。预处理的目的是消除无关信息,突出关键特征。
4.特征提取(Feature Extraction):
在这一步,系统会从预处理后的数据中提取重要的特征。特征是数据中用于区分不同类别的关键属性。例如,在图像识别中,特征可能包括颜色、形状、纹理等。选择正确的特征对于模式识别的成功至关重要。
5.利用提取的特征对数据进行分类(Classification):
一旦特征被提取,系统就会使用这些特征来对数据进行分类。分类器可以是统计方法、机器学习方法或深度学习方法。分类器的目标是根据提取的特征将数据分配到预定义的类别中。
6.对分类结果进行后处理(Post-processing):
分类后的数据可能需要进一步的处理以提高准确性和实用性。这可能包括错误校正、结果解释、数据可视化等。后处理的目的是确保输出结果对用户有意义,并且可以用于决策支持或其他应用。
识别-训练过程如下:

4.模式分类器设计
4.1分类器训练过程

4.2训练-评价流程
训练和测试过程需要分开不同的样本集

模型的选择和评价:

4.3数据划分方式
•
两个层次的划分
–
Performance evaluation: Training+Test
–
Model selection: Estimation+Validation
•
划分方式
–
Cross-validation (rotation)
•
N
等份,每等份轮流做
Test
,其余部分用于训练
•
Leave-one-out (LOO)
–
Holdout
–
Bootstrapping
4.4泛化性能
•
泛化性能
(Generalization
Performance)
:
测试数据上的分类性能
•
测试错误率跟训练错误率往往是有差异的
•
过拟合/过学习:
用复杂分类器能将训练数据分类错误率降到极低
•
训练数据越多、越有代表性,则泛化性能越好

分类器(模型)复杂度 对泛化性能的影响:

•
训练数据不变的情况 下,分类器越复杂,对训练数据拟合程度越高
•
过拟合情况下,泛化性能会下降,比如下面这个例子

5.模式识别方法分类
5.1根据表示方式分类
tistical: 特征矢量
– Parametric (Gaussian)
– Non-parametric (Parzenwindow, k-NN)
– Semi-parametric (GM)
– Neural network
– Logistic regression
– Decision tree
– Kernel (SVM)
– Ensemble (Boosting)
• Structural: 句法、结构
– Syntactic parsing
– String matching, tree
– Graph matching
– Hidden Markov model (HMM)
– Markov random field (MRF)
– Structured prediction
5.2统计/结构方法对比
1.为什么需要结构方法?
统计方法不能解决的问题主要有以下三个:
– 表示模式的结构(如字符的笔划、部首及其相互关系)

– 长度/大小不固定的模式(如字符串)

• 整体分类:
类别数巨大
(
如,
6
位邮政编码的类别数为10
6
)
– 相互关联的多个物体/部件同时分类

• 如果单个分类+后处理?分割不确定,上下文利用不充分
2.统计/结构方法对比
统计/结构方法对比
| 统计方法 | 结构方法 |
| 训练 | 易 | 难 |
| 依赖训练数据 | 需要大量数据训练 | 小样本情况下性能良好 |
| 分类性能 | 大量样本训练时性能优异 | 大样本训练困难,优势难以体现 |
| 可解释性 | 输出概率(置信度),解释性差 | 结构解释,对outlier鲁
棒
|
| 与人类认知的相关性 | 低 | 高 |
5.3学习方法分类
• 监督(Supervised)学习
– 训练样本有类别标号
• 无监督(Unsupervised)学习
– 训练样本无类别标号,得到数据结构表示或分布
• 半监督(Semi-supervised)学习
– 训练样本一部分有类别标号,一部分没有
• Reinforcement learning
– 学习过程中给出奖惩信号
例如,Deep Mind(被Google收购)基于深度神经网络强化学习的玩视频游戏程序
• Domain Adaptation
– 测试样本分布发生变化,分类器参数自适应
5.4生成/判别模型
•
生成
(Generative)
模型:
表示各个类别内部结构或特征分布
p
(
x
|c)
•
判别
(Discriminative)
模型:
表示不同类别之间的区别,一般为判别
函数
(Discriminant function)
、边界函数或后验概率
P(c|
x
)
•
生成学习:
得到每个类别的结构描述或分布函数,不同类别分别学习
•
判别学习:
得到判别函数或边界函数的参数,所有类别样本同时学习





















 54
54 0
0


 已为社区贡献1条内容
已为社区贡献1条内容

所有评论(0)